I’m sorry to bring bad news, but after trying to fight some last minute bugs in the new Gmail resource today, I realized that pushing the resource into KDE Applications 4.14 was too hurried, and so I decided not to ship it in KDE Applications 4.14. I know many of you are really excited about the Gmail integration, but there are far too many issues that cannot be solved this late in 4.14 cycle. And since this will probably be the last 4.x release, shipping something that does not perform as expected and cannot be fixed properly would only be disappointing and discouraging to users. In my original post I explained that I was working on the Gmail integration to provide user experience as close as possible to native Gmail web interface so that people are not tempted to switch away from KMail to Gmail. But with the current state of the resource, the effect would be exactly the opposite. And if the resource cannot fulfil its purpose, then there’s no point in offering it to users.
Instead I will focus on implementing the new native Gmail API and merging together the existing Google resources to create a single groupware solution that will provide integration with all Google’s PIM services - contacts, calendars, tasks and emails.
I already teased publicly about the new Gmail resource on Google+ yesterday, now it’s time for some more explanations and…screenshots!
What is this about?
A native Gmail Resource for Akonadi that will bring much better integration of Gmail features into Kmail.
I’ve been talking about it and promising it for quite some time. But now thanks to some changes to the regular IMAP Resource that Christian Mollekopf has done recently, I could finally start working on it!
But…why?
Those who use Gmail know that Gmail does some things differently than most normal mail services. The biggest difference is that there are not really any folders with emails. Instead there’s one folder with all your emails and then there are labels, that you can assign to emails and then you can just filter your emails by the labels. And you can assign multiple labels to one email.
Yeah, but why bother? It already works quite well with the normal IMAP resource, right?
Yes, Gmail is able to hide this specialities from regular email clients so that they can still work with Gmail like with any other generic mail server, but at the cost of losing some features.
More and more often you can hear today that desktop email clients are dead and the future is in webmail (and cloud). And for many users who only have one email account this is true - why having KMail and KOrganizer etc. running, when they can have all this and more opened constantly in a single tab in their web browser? And the truth is, that Gmail is simply the largest mail provider in the world today. So if we want to persuade all these users to keep using KMail, we need to provide a user experience that is as close as possible to the native web interface. And for that we need a native Akonadi Resource ;-)
(Note: I’d like to avoid flamewars about “desktop clients are not dead vs. are dead” - I believe they are not dead for people who use more than one email account. They will cling to desktop clients until the dawn of the Gods, and even longer, but for normal users with just one mail account, it might be just matter of years to leave desktop clients. But who knows. impossible to see the future is).
Ok, so what’s the difference between Gmail and IMAP Resources?
The Gmail Resource supports some Gmail-specific IMAP extensions. In other words, it can speak and understands Gmail’s IMAP dialect. This means that the Gmail resource can handle the Gmail specifics better than the generic IMAP Resource:
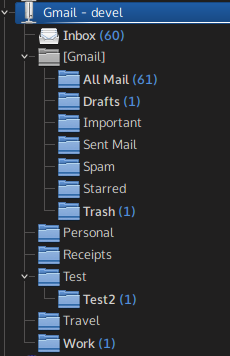
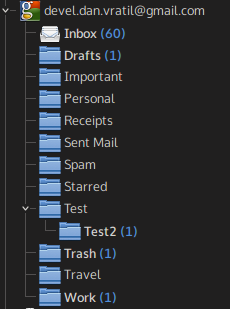
Flattened folder hierarchy. This is best shown on screenshots: on the left, there’s a folder hierarchy as shown in KMail when using the current IMAP resource, on the right there’s the same account but synced via the new Gmail resource.
One email to rule them all! As explained above, one email on Gmail can have multiple labels. But when you sync the mail via normal IMAP, you get a copy of that email in each folder. That means, that marking the mail as read will only mark as read that copy, but not the other copies in other folders, simply because KMail does not know they are effectively the same mail.
The Gmail resource is aware of this, an it syncs all your emails into one hidden folder and then just links them to the actual folders representing Gmail labels that you can see in KMail, so when you mark an email as read in any folder, it will mark it as read in all folders it’s linked into. Awesome, right?
OAuth authentication. The regular IMAP resource only supports the regular username-password authentication (and GSSAPI), which means that your password is stored in the computer somewhere, and if you use 2-step verification, you need to generate an app-specific password.
The Gmail resource has support for Gmail’s OAuth2, so you only enter your password once into Google’s web login, and the resource will then use a special tokens issued by Gmail with limited life-span to authenticate all your requests.
The authentication is actually powered by LibKGAPI, a Qt/KDE library that implements various Google APIs, so it has the same look and uses the same code as the Akonadi Resources for Google Calendars and Google Contacts.
(Funny story and a question: I actually had to write a custom plugin for Cyrus-SASL to support XOAUTH2 mechanism, as upstream does not support it. Does anyone know whether there’s an existing implementation somewhere on the interwebs that I could use instead my crappy plugin?)
Simpler configuration. This is not really that big, bacause you don’t open the dialog very often, but I really like the configuration dialog a lot: simple and without complex options like encryption, mechanisms… This is simply because Gmail supports only a specific set of IMAP features, so I could just remove lot’s of stuff from the configuration dialog making it thinner and much easier to understand (IMO).
Push-notifications for all folders. The IMAP Resource can only monitor one folder for changes (using IMAP IDLE), because of certain technical restrictions. The folder usually is the Inbox. So if you have server-side filtering, you will never get push-notifications about new emails arriving to your other folders.
The limitation for watching only one folder applies to the Gmail Resource too. However since we understand Gmail, we can watch the “All Mail” folder, instead of the Inbox, so this way we get push notifications about emails from absolutely all folders (except for Trash and Junk folders, but who cares about these). Thinking about it, I could even remove the “Check Interval” option from configuration now.
Uhm ok, so what’s the state of the resource?
Currently the resource is still in a branch, waiting for some more features to be finished and for Christian to approve some of my changes to the IMAP resource (I’ll bribe him with some beer during Akademy, if necessary ;-)), and some changes must be done in KMail to properly support copying and moving of the linked emails, but other than that, it already works quite nicely :-)
The KDE PIM Sprint is over (unfortunately…I could do this every day :-)), so now it’s time for some recap of what has been done. I’ll try to cover the Akonadi side, and leave the rest up to others to cover their projects ;-)
Akonadi Server optimizations
We finished and reviewed Volker’s old branch with a big optimization of the database schema. On my computer it reduces size of the file with the largest table by 30% and it speeds up all queries on that database, because the WHERE condition now has to perform only integer comparision, instead of string.
This however means, that we have to migrate user’s database on start. During the migration it is not be possible to use any Akonadi-based applications. We improved the code so that the migration takes about 10 minutes on my computer (used to take 20 and more). I personally think that it’s acceptable “downtime” for a one-time migration, so after I finish testing the migration code on other backends, I’ll merge the branch to master and we’ll ship it with KDE 4.13.
There's always time for a beer!
Server-side Search
When using online IMAP, only headers are in Akonadi, the body is downloaded on-demand when the message is opened in KMail. This means that Nepomuk can’t index these emails and thus can’t include them in search results. To fix this case, we want to make use of IMAP’s SEARCH functionality. We simply ask Nepomuk to search it’s database of indexed emails, at the same time we send IMAP server the same search query and then we just merge results and show them to users. Most of the infrastructure in Akonadi Server has been in place for a long time now, so I’ll just undust it, adopt it to our current needs and we should be good to go ;-)
Using Akonadi to store tags
Working on tags!
I already mentioned this in the previous report: we want to cache tags in the Akonadi database and write them to storage backends if they support it (for instance as additional flags to emails on IMAP server, as CATEGORIES into events in iCal, etc.). Thanks to it it will be possible to share tags between multiple computers, yay! We just need to modify the Nepomuk libraries, so that when you ask Nepomuk for all data tagged with “Holiday”, Nepomuk can search it’s own database and also query Akonadi. Another benefit will be that filtering emails in KMail by tags will be much much faster, because the relation will be stored locally in Akonadi and we won’t have to talk to Nepomuk, which is very slow (mostly because of Virtuoso).
[…] KMail has the second best threading in the world, I think, second only to mutt because that is faster. […]
Why can’t KMail just have the very best threading in the world? Because right now it has to fetch the entire folder from Akonadi in order to be able to perform Subject comparision when building threads. That’s both very slow and CPU-intensive operation. So we thought: let’s store information about relations between emails in Akonadi, and when KMail asks for content of a folder, we give back only first few conversations just to fill the screen, and then fetch remaining conversations on demand when user scrolls down. This should make opening even massive folders superfast and should save a lot of memory, too.
Akonadi and KDE Frameworks
Hopefully David's code is more stable than his towers :)
The most-awaited discussion of the entire sprint was about KDE PIM and KDE Frameworks. When should we start? What has to be done? What can we use this opportunity for? From Akonadi point of view I want to do several things: remove deprecated API, change some API so that we use consistent naming and separate UI and non-UI stuff. Volker Krause suggested that we could move the client libraries into Akonadi repository with Akonadi server, so thatwe could share some of the code (protocol parsers for example), which I like, so we’ll go for that, too.
A bit unrelated, but still: the Akonadi server already compiles with Qt 5 for a while, so possibly during this development cycle we might switch to supporting only Qt 5 (and making use of all the C++11 awesomeness). There’s a little library that kdepimlibs link against, so we just build both Qt 4 and Qt 5 versions of it. Akonadi depends only on QtCore and QtDBus, so we only need distros to ship qt5-qtbase, which we believe most of them do by now.
Gmail resource
Vishesh and Àlex (Photo by Lukáš Tinkl)
I’ve been promising this for ages, now I finally discussed this with others, got some input and can start hacking :-) Let’s see if I can do something before Christmas ;-) Gmail resource would store all your mails in one folder and would create virtual folders for each label and just link emails from the “All mails” folder into respective labels. This way the emails will share flags (read/unread), and you will even be able to manage the labels by linking or unlinking emails from label folders in KMail.
Here I’d like to thank everyone for coming to Brno - if was a lot of fun and great pleasure to see all of you again, and also thank Red Hat for letting us use the office. Looking forward to see you all again on FOSDEM, next sprint, Akademy or anywhere else :-)
we have a little favor to ask from you :-) On the KDE PIM Sprint we discussed how to improve email threading in KMail by using Akonadi to store the information, so that KMail does not have to compute it every time. This would make opening a folder almost instant, all threads would be reconstructed immediately and it would massively improve CPU and memory consumption (so it’s totally something worth helping us with ;-)) More details on what else we discussed and implemented will follow in another blog post tomorrow.
To implement the threading caching, we need to know, whether in these days it still makes sense to support threading by Subject. It’s used as a fallback when grouping by standardized email headers (In-Reply-To, References) are missing, which used to be a case with buggy email clients years ago, but hopefully is better now, so we could drop it, which would massively simplify the algorithms.
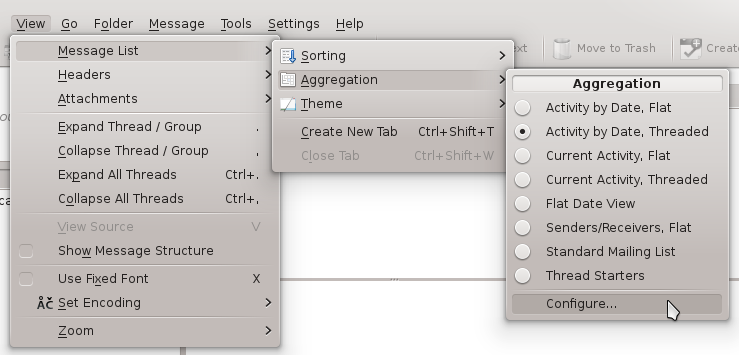
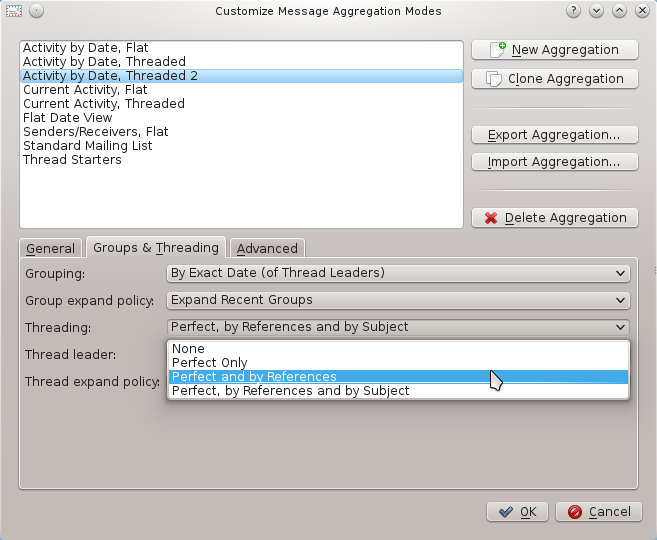
So we would like you to disable threading by Subject, observe how much it breaks your threading (and potentially your workflow) and report back to us. To disable it, go to View ->Message List ->Aggregation -> Configure. There go to Groups & Threading tab and in Threading combobox select Perfect and by Reference. If the combo boxes are disabled, you have to click Clone Aggregation to clone the default settings, and use the clone.
View->Message List->Aggregation->Configure…
Aggregation Configuration
Aggregation Configuration
If removing threading by subject would break threading and workflow for too many users, we will keep the settings and we will try to figure out another way to do it.
So please configure your KMails, and let us know in comments below this post, on IRC, kde-pim mailing list or through any other communication means (just please try to avoid using smoke signals and pigeons ;-))
The KDE PIM sprint in Brno, Czech republic starts this Friday, but some KDE developers just could not wait and decided to come to Brno already on Monday to work with the Red Hat KDE Team. Some of the stuff we are hacking right now is PIM related, but we also want to use this few days to work on other projects that we are involved in, but that are not strictly related to KDE PIM.
So I’m just sitting right now in the office with Àlex Fiestas, David Edmundson, Vishesh Handa, Martin Klapetek and my colleagues Jan Grulich and Lukáš Tinkl. I’m waiting for Àlex to finish polishing his port of BlueDevil to BlueZ5, so that we can start hacking on KScreen - there are far too many bugs that need our attention and we’ve been neglecting KScreen quite a lot in the past few months. We want to fix the annoying crash in our KDED module, solve a regression that my bold attempt to fix an another crash in KDED caused and discuss the future direction of KScreen - me and Àlex have different opinions on where we should go next with KScreen so this is a great opportunity to find a common path :-)
Vishesh has been relentlessly working on improving the semantic technologies in KDE and from what I’ve seen, it’s something to really look forward to ;-)
Yesterday, me and Vishesh discussed the possibility of using Akonadi for handling tags of PIM data (emails, contacts, events, …) and I implemented the feature into Akonadi and the Akonadi client libraries - only as a proof of concept though, I have no intention of shipping it at this point - much more work and discussion is needed about this. I also made further progress with implementing the IDLE extension to the Akonadi protocol. It allows the Akonadi server to send notifications about changes to clients using the Akonadi protocol, instead of D-Bus (performance++)
KDE hackers fighting bugs and bringing the awesome to our users
David Edmundson and Martin Klapetek have been working on creating Plasma theme for SDDM (a new display manager that for example Fedora intends to ship instead of KDM), and today they’ve been improving KPeople, the meta-contact library used by KDE Telepathy and that they will also integrate with KDE PIM.
My colleagues Lukáš Tinkl and Jan Grulich are working on plasma-nm, the new Plasma applet for network management in KDE.
More people will arrive to Brno tomorrow and the rest of KDE PIM sprint attendees will arrive during Friday, when the real sprint begins. Stay tuned for more news (not just) from the PIM world ;-)
Akonadi 1.10.3 has been released, fixing (among other things) support for PostgreSQL 9.2 with Qt 4.8.5.
I write a blog specially about this update, because the fix requires updating the Akonadi database schema. The update will be performed on next Akonadi start and it can take some time, especially on larger databases, so we kindly ask users for patience.
Update: if your distribution ships Qt 4.8.5 with the PSQL driver patch reverted, please make sure to remove the revert before pushing Akonadi 1.10.3 to repositories.
Users of other backends (MySQL or SQLite) will not be affected by this update.
Big thank you for investigating and fixing this problem to Cédric Villemain.
Full changelog:
Fix crash when there are no flags to update during flags change
Fix crash on Akonadi shutdown when using PostgreSQL
Fix notification to clients about database upgrade
Send dummy requests to MySQL from time to time to keep the connection alive
Bug #277839 - Fix problem with too long socket paths
Bug #323977 - Check minimum MySQL version at runtime
Bug #252120, Bug #322931 - Use text instead of bytea column type for QString in PostgreSQL
Thanks to Volker Krause, Christian Mollekopf and Cédric Villemain for their contributions to this release.
I arrived back home from Akademy just a day ago and I already miss it. I enjoyed every single moment of it and had lots and lots of fun. Thanks everyone for making this such an awesome event, and especially to the local team. They did an incredible job!
This blog however will not be about Akademy (I will write one maybe later), but about Akonadi, core component of our PIM suite. As you probably already read or heard, Volker Krause has handed over to me maintainership of Akonadi. It means really lot to me and I’ll do my best to be at least as good maintainer as he was (if that’s even possible) and I would like to thank him for his outstanding job he did writing and maintaining Akonadi.
I really believe in Akonadi, I like design of the framework and admire all the work guys have done on it since the beginning, long before I even dreamed about becoming a KDE contributor. I also believe that having a powerful and well-working PIM suite is the key for success of KDE (not just) in the enterprise world. Akonadi is more powerful than most of the competition out there, we just now need to focus bit more on stability and performance. I think we are doing pretty fine with stability, so I want to focus mainly on the performance side of Akonadi. In this bit more technical blog post I want to write about what I did recently, what I’m doing know and what are (some of) my future plans with Akonadi. As usually, huge thank you to Volker for his ideas, suggestions and comments about my ideas. We had a great discussion during Akademy and we (theoretically) solved many problems and bottlenecks that were bothering Akonadi for a long time, but nobody had time to look into it.
Batch Notifications
I started working on batch notifications after the KDE PIM sprint in March, merged it in May (I think) and hopefully have resolved all regressions by now. Akonadi server uses notifications to inform all clients about changes, like new items, changed items, removed items, etc. Notification is a simple data structure that is transferred via D-Bus to all clients. Before this patch there was one notification per each item which means that marking 500 emails as read had generated 500 notifications that had to be transferred via D-Bus. With batch notifications the server can create a single notification that references all 500 items. This saves a lot of D-Bus traffic and allows faster processing on the client side. This feature will be available in KDE 4.11.
MTime-based item retrieval
This was written during Akademy and will allow Vishesh to improve start-up time of the Akonadi Nepomuk Feeder. Until now the feeder had to fetch all items from Akonadi and all items from Nepomuk on start just to compare whether everything is up-to-date. With mtime-based item retrieval the feeder can ask Akonadi to hand over only items that have been changed since some given timestamp. In most cases that means 0 items. You have to agree that fetching no or just a few items instead of all of them will give us a notable performance boost during start. Albert allowed us to backport this to 4.11, so you will get this improvement in 4.11 as well.
External payload files without path
Another thing that has been implemented during Akademy is aimed to save some of your precious disk space. Because Akonadi is a cache for your data, it means that it has to store all your emails, contacts, events etc. somewhere. Smaller records are stored directly in the database. Larger items are stored in external files on your hard drive and there is only file path stored in the database. However the path is always the same and is usually around 50 characters long, while the file name is only around 10 characters long. This patch makes sure that only the file name without path is stored in the database, saving some disk space. Clients now also have the capability to understand file names without path in server replies, so we can even reduce size of traffic between server and clients a bit. I know that 50 bytes is not much, but multiply it by tens or hundreds of thousands of items, and it’s already worth it. As a side effect, all newly created databases will be relocatable, because all file paths are relative, not absolute. There is no plan to make an automated migration to strip the path from existing records, but I might one day implement this in the Janitor, so that users can migrate their database manually if they want to. But it’s not a priority now.
Server-side monitoring
Previously I explained that Akonadi sends notifications via D-Bus to all clients to inform them about changes. The problem here is that not all clients are usually interested in all changes. For instance KOrganizer does not care about new emails and KMail does not care about modified appointments (there are exceptions like the Nepomuk Feeder, which listens to everything for obvious reason). Yet each notification is “broadcasted” to all Akonadi clients. Each client then decides whether it’s are interested in the notification and wants to process it further or just drops it. The average number of clients is around 16, but in most cases only 3 or 4 clients are actually interested in each notification. That means that other 12 or 13 clients just drop the notification. What I’m working on right now is to move this filtering code to the Akonadi server, so that the clients can tell the server what kinds and types of notifications they want and the server will only send notifications to those clients that are really interested in it. This should save us a lot of D-Bus traffic and will fix the awkward situation when all clients are consuming CPU, even when you are just syncing one of your IMAP accounts.
Server-side change recording (IDLE)
The biggest task ahead of me. Some Akonadi clients are using feature called change recording. That means that every notification that is not dropped by the client is stored into a binary file (every client has one such file) and is removed again when the client confirms that the notification has been processed. This is used for example by the IMAP resource. When you are offline the resource is recording all notifications (about items being deleted, moved between folders, marked as read, etc) into the file and when you connect to the internet and the resource is switched to online all notifications are replayed from the file. My plan is to implement something similar to IMAP’s IDLE. Changes will be recorded on the server instead of the clients and all clients will be able to connect to the server and request all pending notifications. After that they send “IDLE” command + explanation of what kind of notifications they are interested in and the server will automatically feed them with new notifications. This is essentially continuation of the “Server-side filtering” feature, but it takes it to a completely new level. With this feature the Akonadi framework will generated almost no D-Bus traffic at all and the whole thing will be much much faster. I’m really looking forward to work on this because it’s a very challenging task and the result will definitely be worth the effort.
Volker has also submitted a few patches to reduce size of the messages sent between clients and server even more and started working on optimizing some SQL queries so that we don’t query the database for data we don’t actually use anywhere.
Of course there are more smaller ideas and improvements in the queue, but I need to keep something for next blog posts so stay tuned - there’s more coming soon! :-)
I haven’t blogged about my involvement in KDE PIM in a while, so let’s see what’s new there, especially in the Google integration part….
Reborn Google Resources
Just before the KDE PIM sprint in Berlin this month, I’ve sat down and written completely new API for LibKGAPI (the library that implements Google API and is used by the Akonadi resources for Google services). The new API is job-based, and therefore much more awesome than the old one (which is known to suck). Anyway - what does this mean? It means that the new resources are awesome as well!
Google Contacts resource now has a full support for contacts groups. All contacts are stored in the top-level collection and are linked to the respective groups, so it does not matter where you edit the contact, you are still modifying the same instance. Like in the web interface.
Google Calendar now supports limited sync, so you can choose to only sync events from last year, or last two years (the default is last 3 years) instead of the full history.
Both resources have improved status reporting, error handling, are more stable (no more mystery crashes due to unhandled exceptions thrown from LibKGAPI) and subjectively synchronization is faster too.
Murdered Google Resources
As most of you probably noticed by now, Google is planning to shut down Google Reader by July 1. It’s pitty, because I already had a fully working Akonadi resource for Google Reader ready in the akregator_port branch. Cost me lot of time and nerves. Well, the resource is not there anymore and the only memory of it is greader branch with API implementation in LibKGAPI (which will die as well sooner or later). The good news however is that I can now help Alessandro and Frank with ownCloud News and the ownCloud Akonadi resource, so that we rock when Akregator2 is out :-) I can’t wait to see what has changed in ownCloud since I installed 3.0.0 some time ago…
Upcoming Google Resources<
I have two feature requests in bugzilla: one is to support Google Bookmarks, which is fairly complicated because of missing official API and absolutely no write API. So this is not going to happen soon. The second feature request is for Google Drive KIO slave. This is much more interesting task. I already tried writing Google Docs KIO slave about three years ago and I failed epically. Retribution! There’s almost complete API implementation by Andrius in LibKGAPI git, so I plan to port it to LibkGAPI2 and see whether we can together fight the Dark side and create a nice and shiny KIO slave.
Finally, deep in the dark corners of my mind, my so far the most evil plan is slowly shaping. The plan includes modifying the current IMAP resource, reusing most of it’s code and subclassing some specific parts to build a native GMail Akonadi resource that would support some GMail-specific IMAP extensions. The main idea is to support one-mail-in-multiple-folders-at-once case. Right now the IMAP resource handles that by creating a new instance of the same email in multiple folders. My bold plan is to store all emails in Inbox and link them to respective folders. This means that marking an email as read in one folder, will automatically mark it as read in all other folders (because it’s a single instance). The IMAP resource looks scary though, so I don’t know yet when I’ll get the courage (and time) to sit down and actually start coding…I guess probably after Akademy, after I talk to some people.
Batch Operations in Akonadi
I have talked to Volker Krause during the KDE PIM sprint about how to effectively handle “Mark feed as read” in the Google Reader resource. Currently, Akonadi creates a new notification for every change, therefore marking 300 items as read generates 300 notifications, which are delivered to the Akonadi resource, which should then create 300 HTTP request to store 300 changes. You probably agree that this slightly suboptimal. (I temporarily solved the problem by caching the notifications in the resource itself and then sending a big request to Google Reader at once). The solution that Volker suggested sounds fairly simple (it’s not) - batch notifications - i.e. a single notification about single change involving multiple items. The supported changes can be flags change, deleting or linking of items. By being able to deliver single notification about mass-change to Akonadi clients and to Akonadi resources represents new possibilities for optimizations. For instance the IMAP resource could simply send a single command to add a flag to multiple emails at once, instead of doing it one by one. The same goes for other operations and other resources that are dealing regularly with operations on larger sets of items. The obvious result: performance boost! After two weeks the work is in semi-working state - it works, but it goes nuts if more than 5 items are involved. The cause is known, but solution not (but I’ll get there eventually :-) )
Akregator 2
I’m occasionally helping with Akregator2 (Akonadi port of Akregator). Recently (ok, it was two months ago… ) I’ve written Akonadi Nepomuk Feeder plugin that is feeding RSS Articles into Nepomuk and a Search window (slightly inspired by the one in KMail) in Akregator2 where you can do full-text search (+ search via other criteria, including author’s name and date of publishing) based on data indexed in Nepomuk. Obviously, when I wanted to demo that on the KDE PIM sprint I found out that it’s not working as good as I thought, so there’s still some work to be done. But in general I’m happy to say, that from time to time it finds something :-).
Ok, so that’s about what I was, am and will be working on in KDE PIM. Here I’d like to say big thank you to all KDE PIM devs, because they are doing an incredible job. Thank you!
Hi! Nearly four weeks after the [0.3](https://dvratil.cz/2012/04/akonadi-google-0.3-arrives/ release of Akonadi resources for
Google there’s a new version with just a few, but important bug fixes and improvements.
UPDATE: In order to use the Google resources, you either need KDE 4.9 (which the resources are part of), or you need to install LibKGAPI 0.4.1 (or newer) and Akonadi resources fromgit://anongit.kde.org/scratch/dvratil/akonadi-google-resources. See this discussion for details.
Fixed bugs and crashes:
Bug #296541 - Uncaught exception in signal handler in Contacts resource
Bug #297824 - Uncaught exception in signal handler in Calendar resource
Bug #297548 - Crash at akonadi start after having added a new contact - resource
Bug #298519 - Deleting events incorrectly reports an error
The first two bugs were especially tricky as I couldn’t reproduce them, but many users were affected by ugly and
repeating crashes. But now the “Google experience” is much much better :).
Big thanks go to Alex Fiestas who has contributed various improvements to libkgoogle to better work with 3rd party apps
(so now we can be looking forward to his web-accounts wizard :) ).
After many months of “I will release it next week” I finally released libkgoogle 0.3 and new version of Akonadi resources for Google this week.
So, what’s new? I managed to implement everything I described in [this post]( {% post_url 2011-11-25-akonadi-google-resource-whats-comming %} “Akonadi Google Resource: what’s coming?”) back in November. That’s support for multiple Google accounts, and merging the tasks resource into the calendar resource (so now it’s called “Calendar and Tasks resource”). The calendar now properly supports events recurrence and partially exceptions in recurrent events (there’s still some work to be done). The contacts resource now splits your contacts to “My Contacts” and “Others” groups. I hoped to fully support contact groups, the code was even in place, but I’ve run to some problems how to store it in Akonadi and unfortunately KAddressBook is not “compatible” with the Google’s concept of contact groups, so I decided to stick with the two elementary groups and hopefully I’ll get to this later (maybe some PIM dev could help me on Akademy? ;) )
If you run to any problems or bugs, please report them to the libkgoogle product in bugzilla.
Finally, I’d like to thank to Jan Grulich and Vojtěch Zeisek for putting their contacts and events at risk to test the pre-release versions and provided valuable feedback.











{kind=link}